接下來就用實際的程式範例操作
今天用的網頁是:PTT的八卦版
網址:https://www.ptt.cc/bbs/Gossiping/index.html
我們使用上次抓標題的方法試一次,但我們可以發現並沒有抓到東西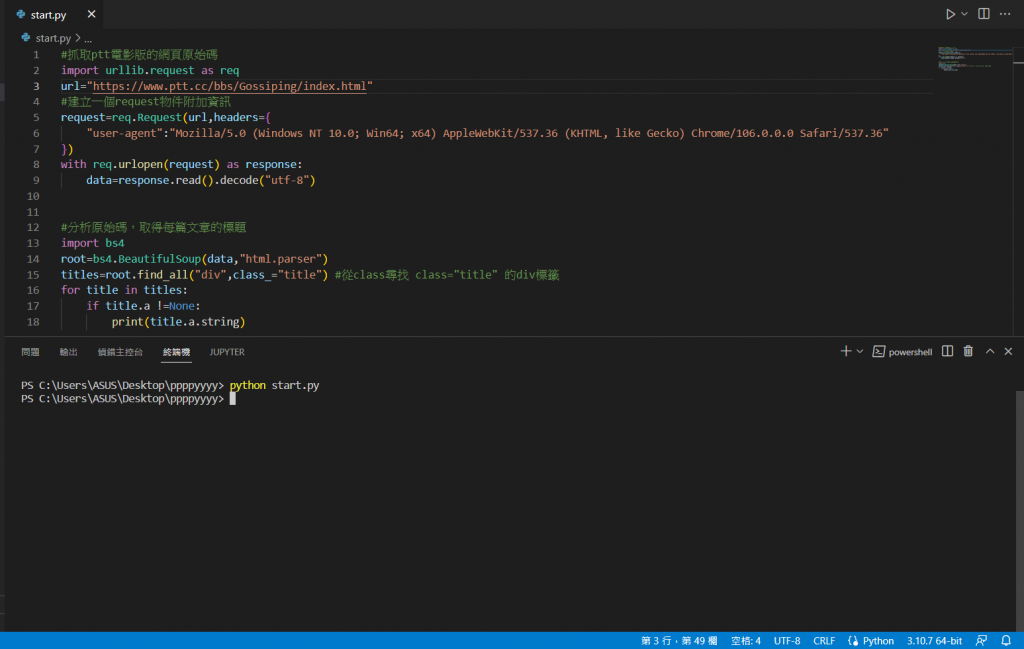
PTT電影版跟PTT八卦版的差別?
八卦版多了一個18歲的確認畫面,這時我們的爬蟲就沒辦法順利抓取程式
這個其中就和Cookie有很大的關聯
這些就是PTT放在瀏覽器的Cookie,裡面的over18就是有無超過18歲的存取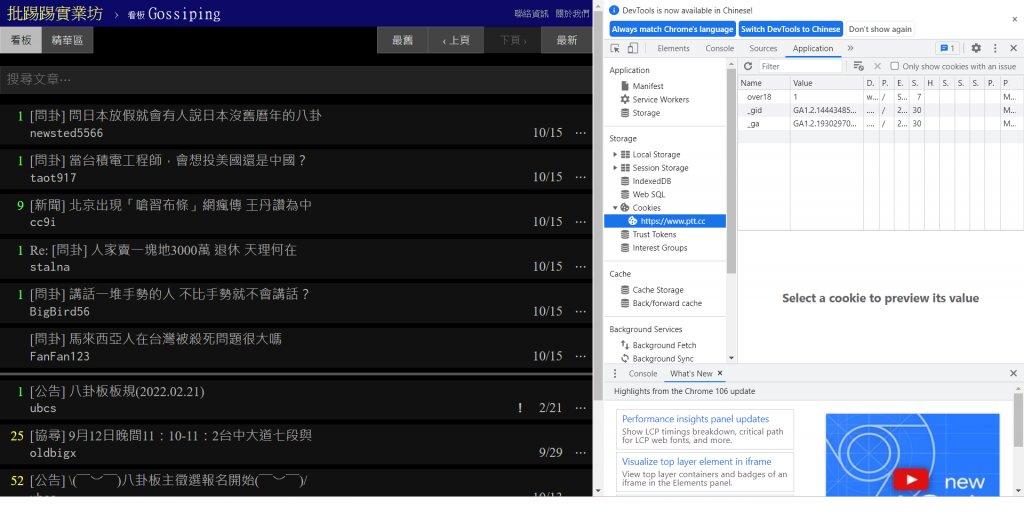
接著進到network頁面的request headers可以找到cookie的資料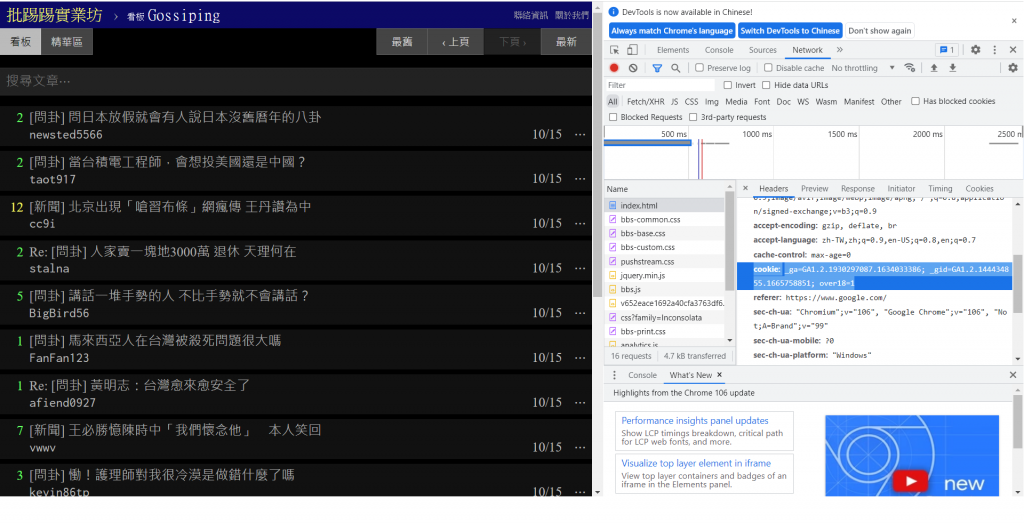
在程式中加上這一行就可以順利的抓取內容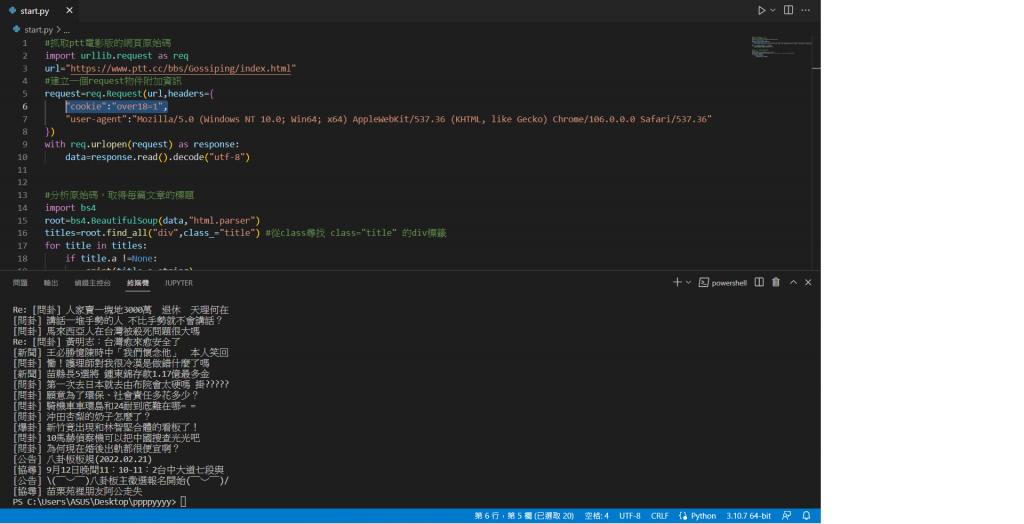
接著我們要讓我們的爬蟲程式不只抓取一個頁面,可以使用上面的超連結抓取多個頁面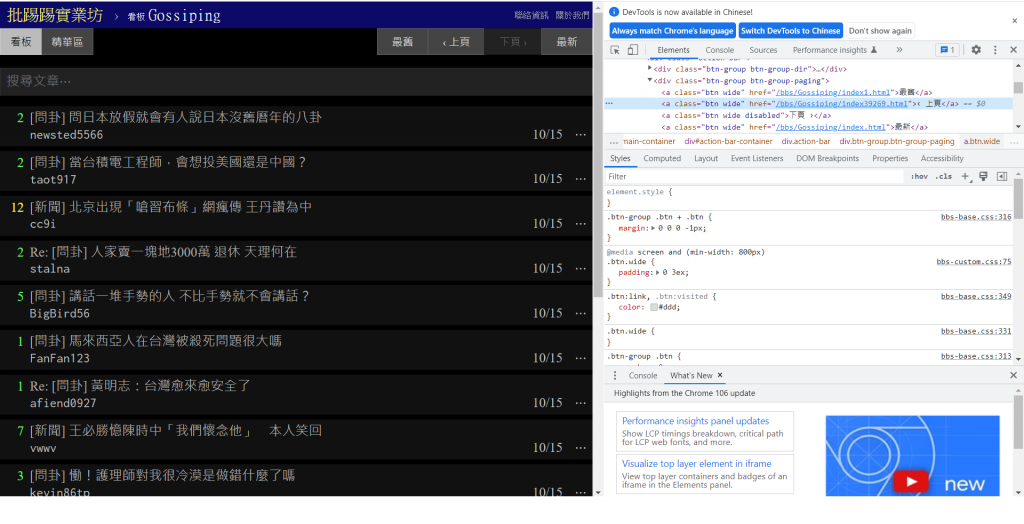
利用(< 上頁)的文字來抓取超連結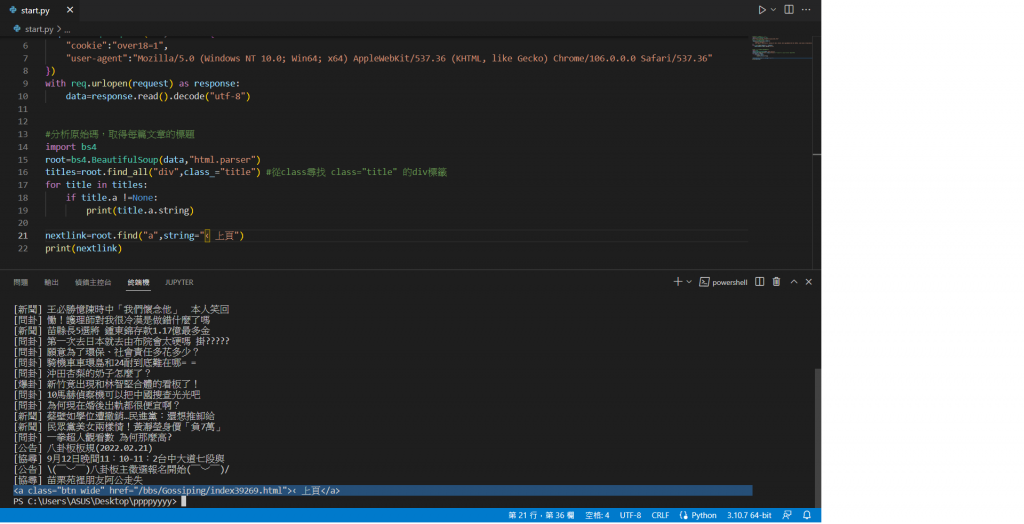
在後面加上屬性的名稱這樣可以得到乾淨的網址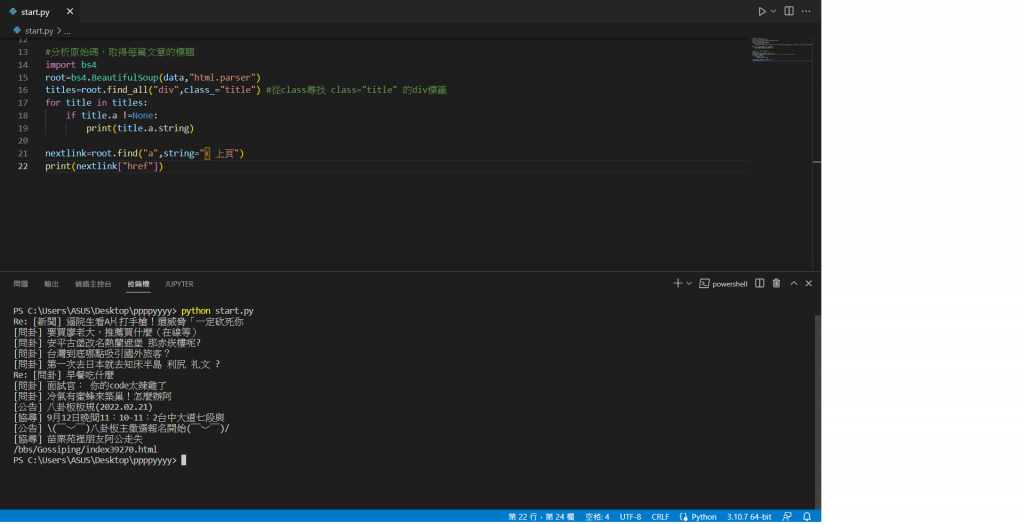
為了要能夠一次抓取多個頁面我們需要包裝程式,將他放到函式內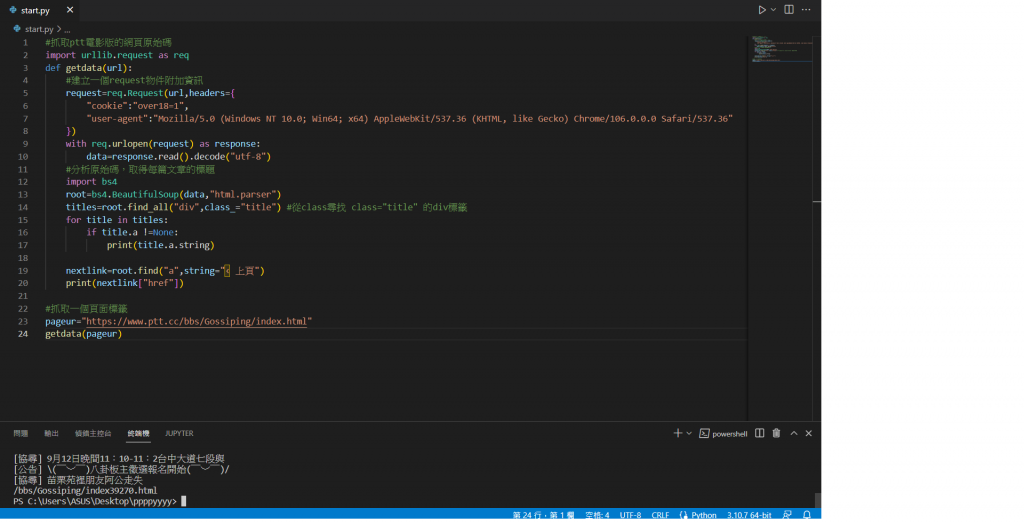
這樣我們成功一次抓取3頁的標題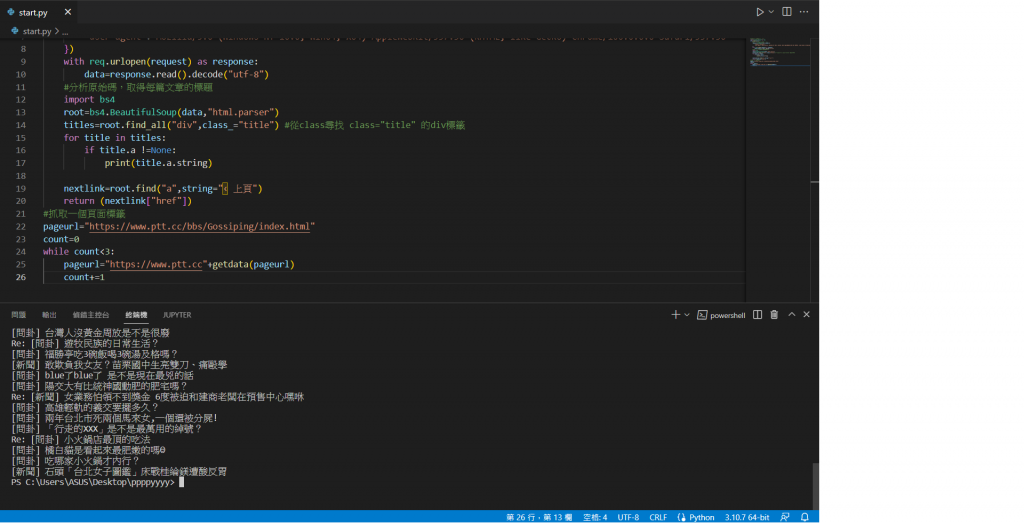
參考來源:https://www.youtube.com/watch?v=BEA7F9ExiPY&list=PL-g0fdC5RMboYEyt6QS2iLb_1m7QcgfHk&index=20
 409261275
409261275

 iThome鐵人賽
iThome鐵人賽